An intro to Machine Learning for designers
The basics of machine learning and how to apply it to the products you are building right now.

There is an ongoing debate about whether or not designers should write code. Wherever you fall on this issue, most people would agree that designers should know about code. This helps designers understand constraints and empathize with developers. It also allows designers to think outside of the pixel perfect box when problem solving. For the same reasons, designers should know about machine learning.
Put simply, machine learning is a “field of study that gives computers the ability to learn without being explicitly programmed” (Arthur Samuel, 1959). Even though Arthur Samuel coined the term over fifty years ago, only recently have we seen the most exciting applications of machine learning — digital assistants, autonomous driving, and spam-free email all exist thanks to machine learning.
Over the past decade new algorithms, better hardware, and more data have made machine learning an order of magnitude more effective. Only in the past few years companies like Google, Amazon, and Apple have made some of their powerful machine learning tools available to developers. Now is the best time to learn about machine learning and apply it to the products you are building.
Why Machine Learning Matters to Designers
Since machine learning is now more accessible than ever before, designers today have the opportunity to think about how machine learning can be applied to improve their products. Designers should be able to talk with software developers about what is possible, how to prepare, and what outcomes to expect. Below are a few example applications that should serve as inspiration for these conversations.
Personalize Experiences
Machine learning can help create user-centric products by personalizing experiences to the individuals who use them. This allows us to improve things like recommendations, search results, notifications, and ads.

Identify Anomalies
Machine learning is effective at finding abnormal content. Credit card companies use this to detect fraud, email providers use this to detect spam, and social media companies use this to detect things like hate speech.
Create New Ways to Interact
Machine learning has enabled computers to begin to understand the things we say (natural-language processing) and the things we see (computer vision). This allows Siri to understand “Siri, set a reminder…”, Google Photos to create albums of your dog, and Facebook to describe a photo to those visually impaired.

Provide Insights
Machine learning is also helpful in understanding how users are grouped. This insight can then be used to look at analytics on a group-by-group basis. From here, different features can be evaluated across groups or be rolled out to only a particular group of users.
Prepare Content
Machine learning allows us to make predictions about how a user might behave next. Knowing this, we can help prepare for a user’s next action. For example, if we can predict what content a user is planning on viewing, we can preload that content so it’s immediately ready when they want it.
Types of Machine Learning
Depending on the application and what data is available, there are different types of machine learning algorithms to choose from. I’ll briefly cover each of the following.

Supervised Learning
Supervised learning allows us to make predictions using correctly labeled data. Labeled data is a group of examples that has informative tags or outputs. For example, photos with associated hashtags or a house’s features (eq. number of bedrooms, location) and its price.
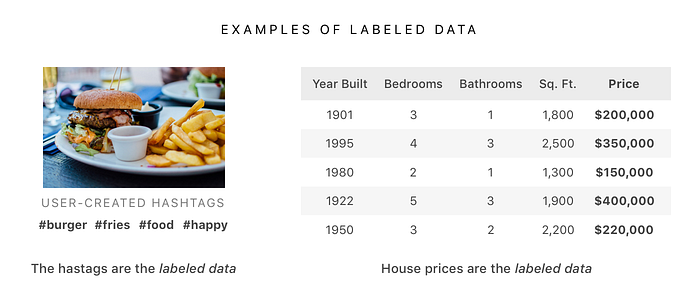
By using supervised learning we can fit a line to the labelled data that either splits the data into categories or represents the trend of the data. Using this line we are able to make predictions on new data. For example, we can look at new photos and predict hashtags or look at a new house’s features and predict its price.
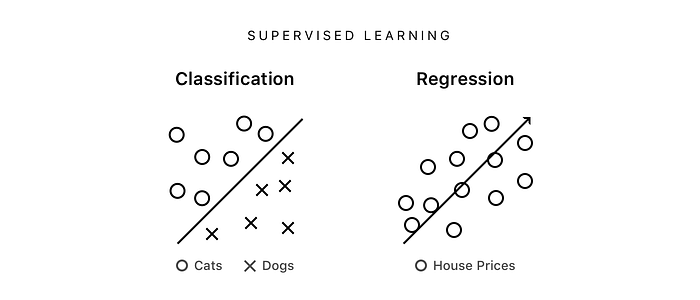
If the output we are trying to predict is a list of tags or values we call it classification. If the output we are trying to predict is a number we call it regression.
Unsupervised Learning
Unsupervised learning is helpful when we have unlabeled data or we are not exactly sure what outputs (like an image’s hashtags or a house’s price) are meaningful. Instead we can identify patterns among unlabeled data. For example, we can identify related items on an e-commerce website or recommend items to someone based on others who made similar purchases.
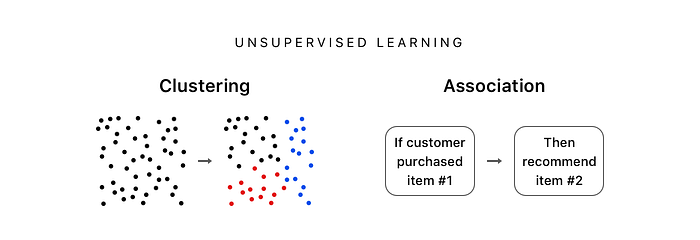
If the pattern is a group we call it a cluster. If the pattern is a rule (e.q. if this, then that) we call it an association.
Reinforcement Learning
Reinforcement learning doesn’t use an existing data set. Instead we create an agent to collect its own data through trial-and-error in an environment where it is reinforced with a reward. For example, an agent can learn to play Mario by receiving a positive reward for collecting coins and a negative reward for walking into a Goomba.
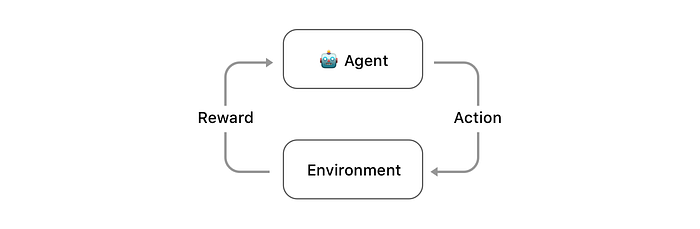
Reinforcement learning is inspired by the way that humans learn and has turned out to be an effective way to teach computers. Specifically, reinforcement has been effective at training computers to play games like Go and Dota.
Things to Consider
What approach is viable?
Understanding the problem you are trying to solve and the available data will constrain the types of machine learning you can use (e.q. identifying objects in an image with supervised learning requires a labeled data set of images). However, constraints are the fruit of creativity. In some cases, you can set out to collect data that is not already available or consider other approaches.
What is the margin of error?
Even though machine learning is a science, it comes with a margin of error. It is important to consider how a user’s experience might be impacted by this margin of error. For example, when an autonomous car fails to recognize its surroundings people can get hurt.
Is it worth it?
Even though machine learning has never been as accessible as it is today, it still requires additional resources (developers and time) to be integrated into a product. This makes it important to think about whether the resulting impact justifies the amount of resources needed to implement.
Closing Thoughts
We have barely covered the tip of the iceberg, but hopefully at this point you feel more comfortable thinking about how machine learning can be applied to your product. If you are interested in learning more about machine learning, here are some helpful resources:
- Machine Learning for Humans — Simple, plain-English explanations accompanied by math, code, and real-world examples.
- Machine Learning Algorithms: Which One to Choose for Your Problem — Tips for developing an intuition for picking a machine learning algorithm to apply to a problem.
- Machine Learning is Fun! — A slightly more technical series that walks through implementing a machine learning example.
- Neural Networks by 3Blue1Brown — A collection of engaging, technical Youtube videos that step through what are neural networks and how they work.
- Andrew Ng’s Machine Learning Course — Highly rated technical course that broadly covers many areas within machine learning.
Thanks for reading. Chat with me on Twitter @samueldrozdov











